Suite
A suite is the set of tasks that together measure one use case
How a suite fits together
A suite is an ordered set of tasks, and the order is part of the design:
- Break the use case into tasks that score in isolation. Each task is one graded step toward the use case being solved
- Let the sequence carry the use case. Read top to bottom, the suite should make sense as one problem being solved
- Isolation is absolute. Every task runs on its own fresh environment; nothing carries from one task to the next. The order shapes how you design and read the suite, never what the agent experiences
- No prescribed count. The pattern says nothing about how many tasks a suite needs; coverage of the use case decides that
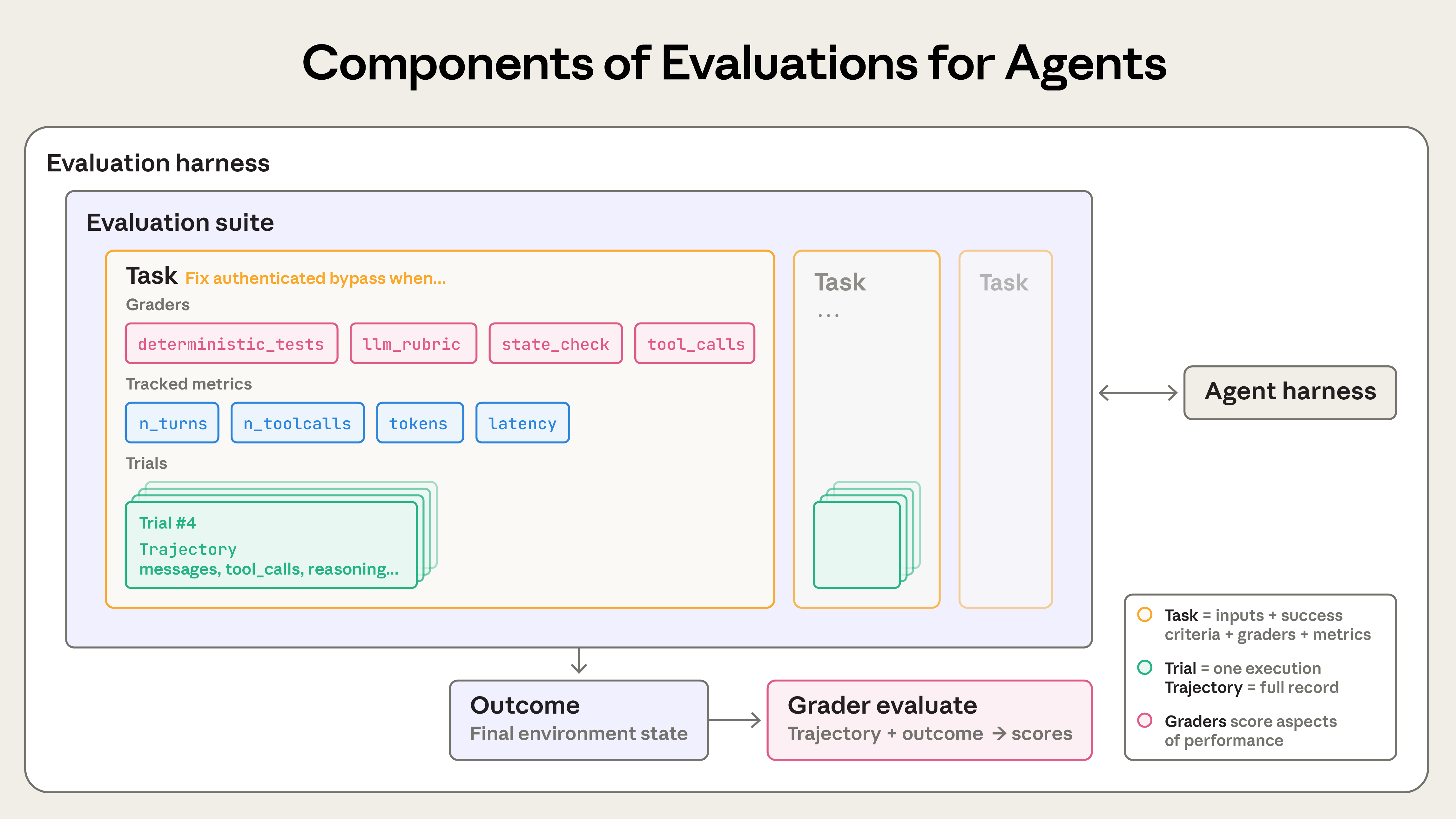 Source: Anthropic, “Demystifying evals for AI agents” (2025).
Source: Anthropic, “Demystifying evals for AI agents” (2025).
Reuse the environment, change the prompt and context
Once the environment stands, another task is cheap: reuse the environment and its tooling, change the prompt and the context, reuse or adjust the grader. The simplest related tasks are variants, the same task made easier or harder. A suite usually spans that range, from a guided variant to the full unaided task
What a whole suite must satisfy
Coverage of the use case. Use the smallest set of tasks that fully measures the use case. Adding tasks the use case does not need does not raise a score; it dilutes the suite
Difficulty spread across the suite. There’s no specific set or range; a good suite holds a variety of tasks, easy to hard, as the use case dictates. If scores all pin at 0 or 1, the spread is too narrow to read progress from.1
Bottleneck diversity. Vary what makes tasks hard: knowledge recall, specification interpretation, multi-constraint satisfaction, preservation under change, debugging from symptoms, architecture reasoning. If every task shares one bottleneck, a small improvement there produces a misleading jump in suite performance
Positive and negative cases. Test where a behaviour should occur and where it should not
Capability and regression suites
A capability suite measures what agents can do today and where they still fail. It should contain hard tasks and leave room for progress. As models improve, scores climb until the suite saturates; once every model passes everything, the suite stops measuring progress
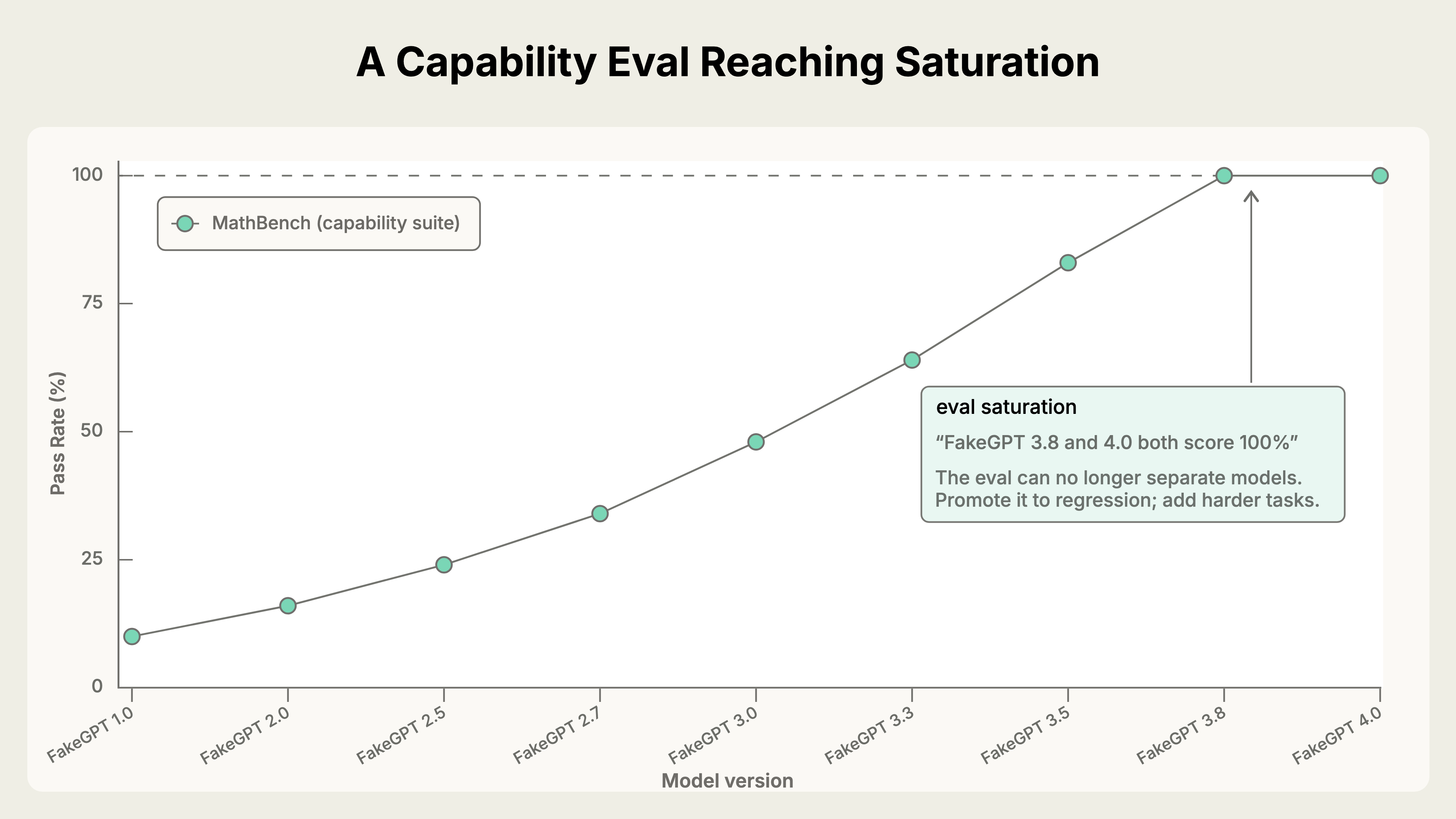
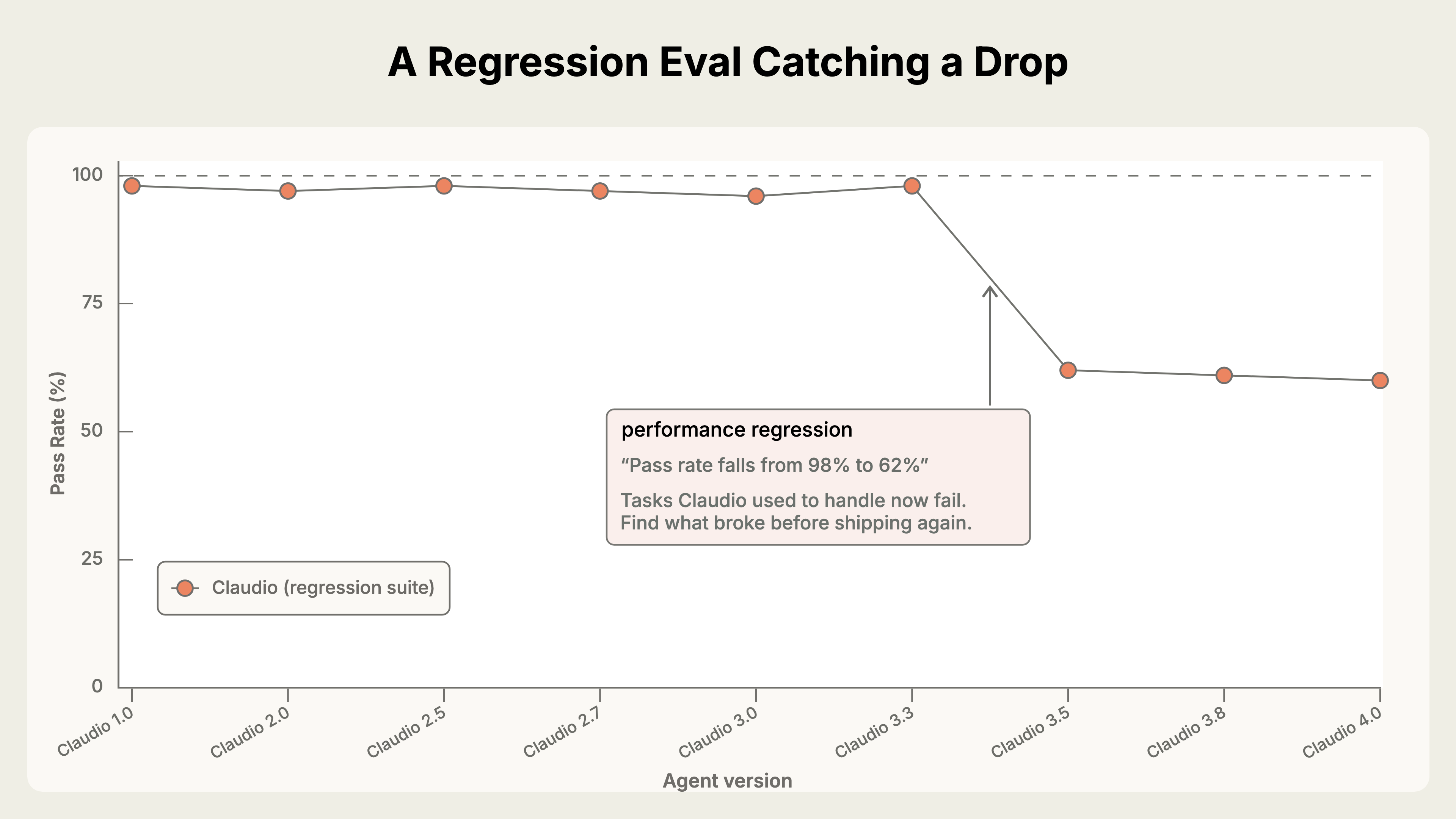
A regression suite protects behaviour the agent should already handle. It should stay close to perfect, so any drop signals that something broke. When a capability suite becomes too easy, promote it into a regression suite and add harder tasks.2
For repeated trials, report the metric that matches the use case. Use pass@k when one successful attempt is enough.3 Use pass^k when reliability matters every time.4 The two metrics move in opposite directions as trials increase.
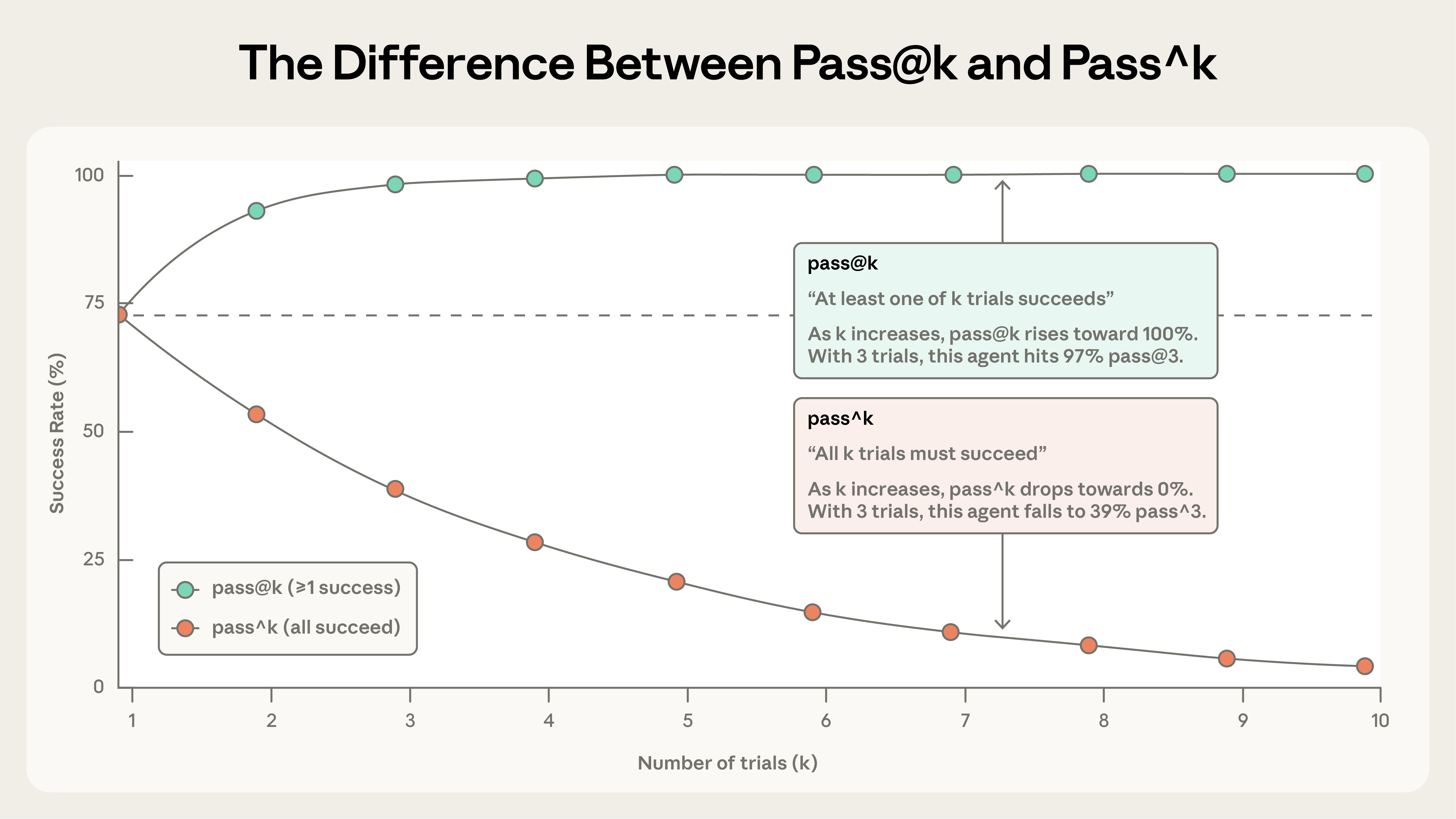 Source: Anthropic, “Demystifying evals for AI agents” (2025).
Source: Anthropic, “Demystifying evals for AI agents” (2025).
Vania et al., “Comparing Test Sets with Item Response Theory” (2021). https://aclanthology.org/2021.acl-long.92/ ↩︎
Kiela et al., “Dynabench: Rethinking Benchmarking in NLP” (2021). https://aclanthology.org/2021.naacl-main.324/ ↩︎
Chen et al., “Evaluating Large Language Models Trained on Code” (2021). https://arxiv.org/abs/2107.03374 ↩︎
Yao et al., “tau-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains” (2024). https://arxiv.org/abs/2406.12045 ↩︎