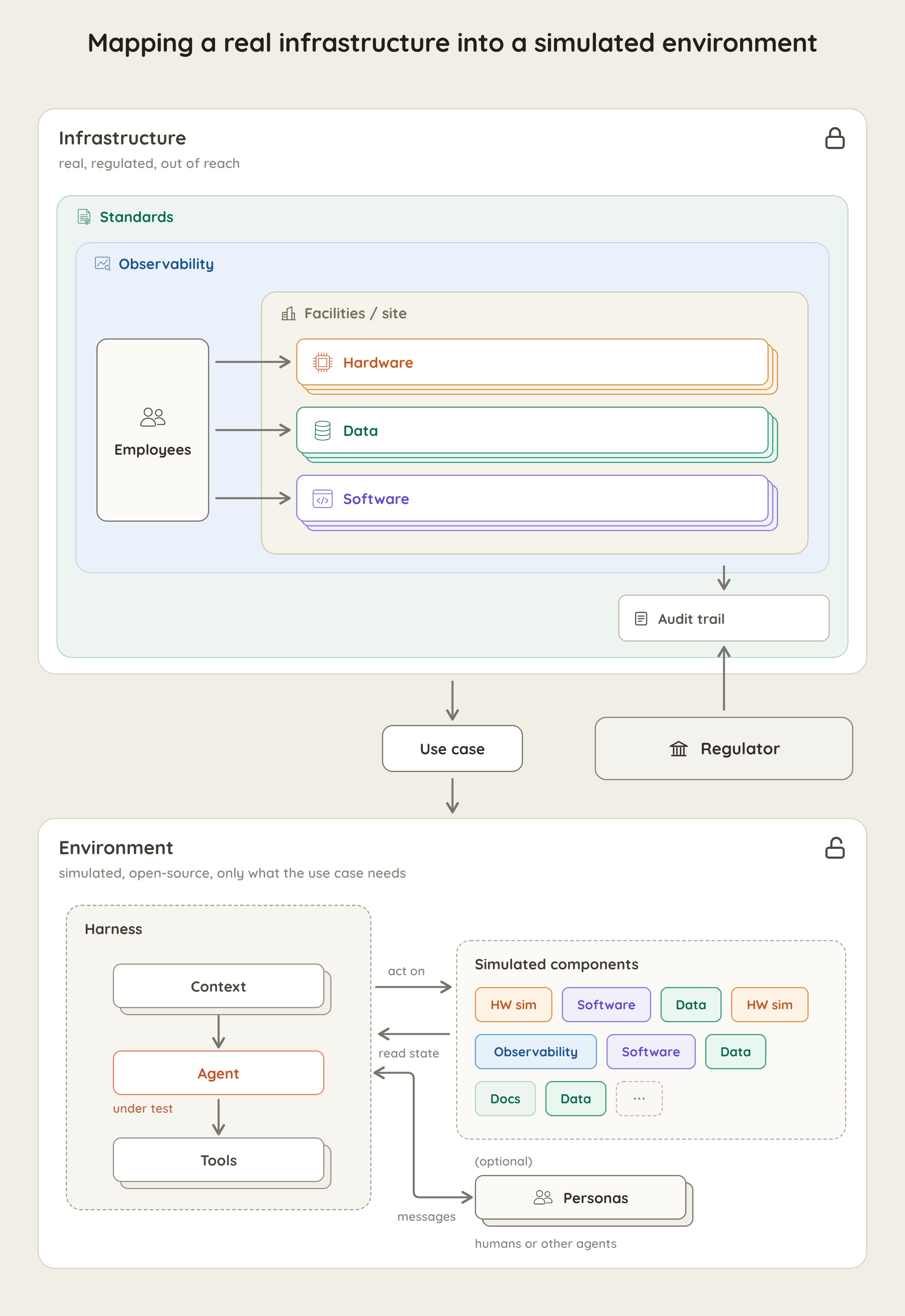
Environment
The environment is the workspace where the agent operates, built in simulation from a recipe: the combination of open-source components that reconstructs the use case and the world around it. It should be realistic enough to let the agent do the task, and stable enough that failures come from agent behaviour rather than sandbox noise
 Source: me.
Source: me.
One environment per use case
Simulating a whole domain is almost impossible; in telecom, every operator runs its own stack. So instead of one universal environment that does everything, like a full digital twin, build a mini digital twin of exactly what the evaluation needs
Work backward from the outcome you want to measure to the smallest world that produces it, and pick tools the agent can act on and the grader can read state from. The same tooling that stands up that environment can also power the grader; the evaluation harness is what boots it fresh for every trial. One use case, one recipe; that environment is what your whole suite runs on
Cheap to run
The environment should be cheap enough to run often. A task runs many times, usually in parallel on different machines, so a score reflects reliability and not a single lucky pass; an environment that takes hours to boot, or is expensive enough that runs get rationed, won’t get run enough to trust. Keep tasks short for the same reason
Fidelity sets the floor on how cheap that can get. Reconstructing real work is hard, and a faithful environment can need a GPU or other specialised hardware, so don’t strip it down so far that it no longer resembles the job
Repeatable by construction
Run the same model on the same task 10 times and the scores should cluster tightly; if they scatter, you cannot tell a real improvement from noise
- Fresh containerised environment each run. Everything starts from a known state; shared state between runs, leftover files, or cached data turn into noise in the score.1
- All reference material local. Standards, schemas, and documentation are available inside the environment; no live APIs, no external services. If a portal goes down or changes its URL structure, the task still works
- Reliable boot and health checks. If startup order or container quirks cause intermittent failures, that is incidental difficulty polluting the score
Anthropic, “Demystifying evals for AI agents” (2025). https://www.anthropic.com/engineering/demystifying-evals-for-ai-agents ↩︎