Agent
With the use case fixed, the next step is to imagine the agent: what kind of harness it would be, and what it would have to be capable of. I spend more time on the capabilities than on anything else in this step, because everything that follows refers back to them: the environment must let the agent demonstrate each one
Name the capabilities
A capability is something the agent must be able to do for the use case to count as solved. Describing the agent is mostly writing this list. For the factory use case, the provisioning agent needs six: infer the technical requirements from a plain-language brief, configure the core, attach the radio, boot and health-check the network, validate it against the KPIs, and repair it when a measurement misses
The list does its real work later, when you design the suite: each task grades one or more capabilities, so the two lists have to account for each other. I check in both directions. A capability no task grades usually means I added something the use case never needed; a task that grades nothing on the list usually means the list is missing an entry
Picture the agent at work
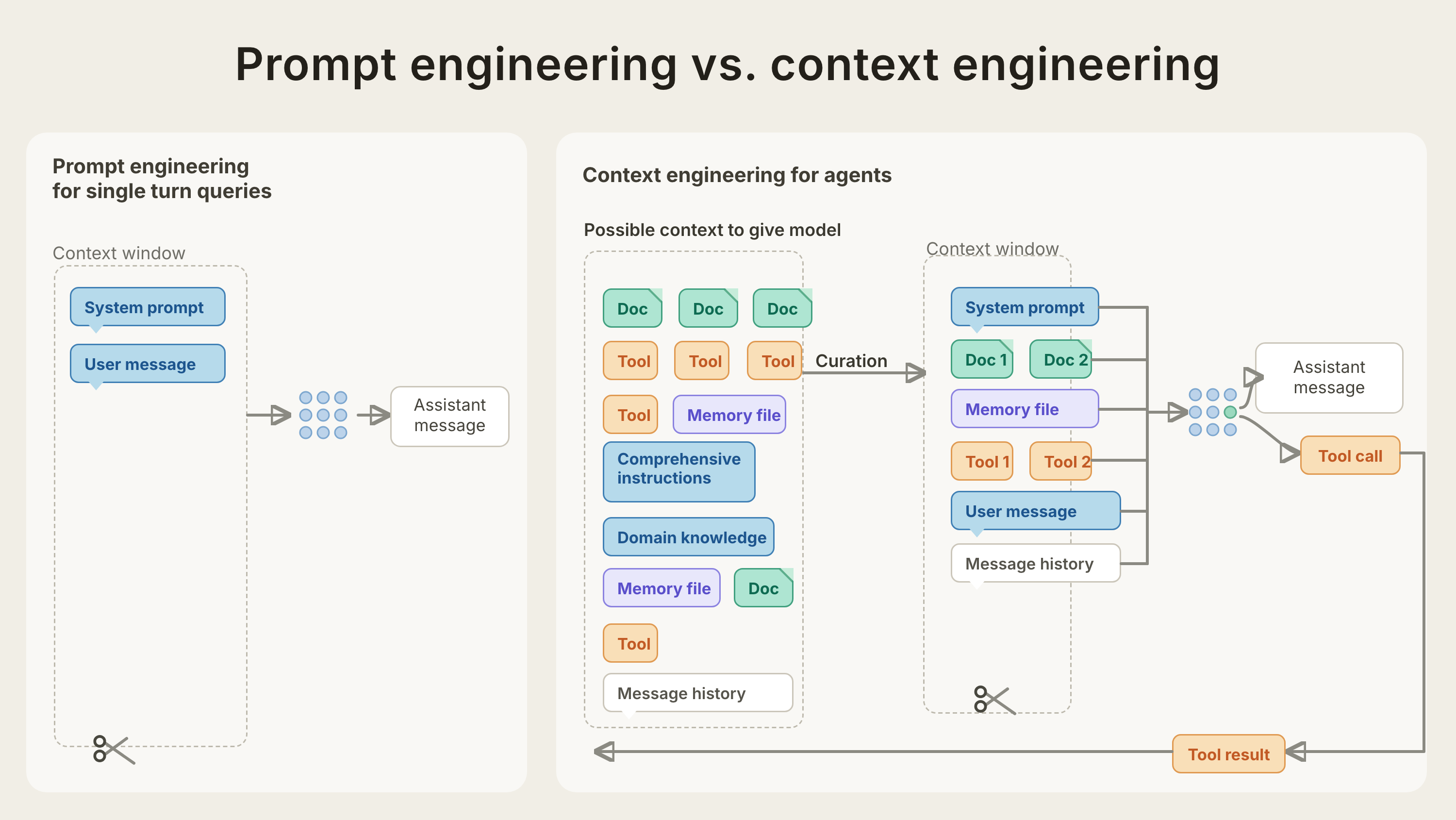
An agent is an LLM autonomously using tools in a loop.1 Each turn it decides, acts through a tool, observes the result, and decides again. One turn is small: read the brief, edit one config, run one probe. A capability is what a run of those turns adds up to. “Validate the network against the KPIs” is one capability, but it takes many turns: drive traffic, measure, compare, fix, measure again. A capability is something the agent does with the loop, not a fact it knows
Three things bound that loop, and good capability lists respect them:
- The context window is the agent’s working memory, and it is finite. Accuracy degrades as context grows.1 A capability like “diagnose from a 50,000-line log” is really two: finding the relevant evidence, then reasoning over it
- The tools are the action surface. Bloated or ambiguous tool sets are one of the most common failure modes; if a human engineer can’t say definitively which tool to use in a situation, the agent can’t either.1 Grant few, clear tools
- Long work crosses context windows. Agents sustain long tasks by compacting their history, taking structured notes, or handing off to a fresh context.2 If your use case needs hours of work, that handoff behaviour is itself a capability to grade
 Source: Anthropic, “Effective context engineering for AI agents” (2025).
Source: Anthropic, “Effective context engineering for AI agents” (2025).
Agent access
Give the agent what a practitioner would reasonably use, without making the evaluation depend on one specific agent setup. The agent harness, or scaffold, is the system that makes a model act as an agent: the core loop that orchestrates the interaction between the user, the model, and the tools the model invokes.3 Evaluating an agent means evaluating the harness and the model together
Harness engineering. The next practice level up from context engineering. Anthropic describes context engineering as the natural progression of prompt engineering: less about finding the right words, more about which configuration of context produces the behaviour you want.1
The evaluation harness is everything on the other side of the task, and the two stay separate. Do not bake a particular agent harness into the task: describe the scenario, evidence, success criteria, and grading logic clearly enough that different capable agents can sit the same evaluation. If Claude Code can solve the task with its own tools, another capable agent should be able to sit it too
Leave the tools for last
I leave the tools for last. Building an evaluation from scratch, I write them only once the suite exists: the tasks tell me which actions the agent has to take, so I build those and stop there. Tools added before the tasks tend to go unused, and a tool the agent never calls is still context it has to read and reason about
What I keep, I write as a clear action.4 A good description does four things:
- Opens with the action. The first words say what the tool does, so the agent can pick it from the list without inferring it from the name or the schema
- Says when to use it, and when not to. Where two tools overlap, the description names the other one
- Shows a worked call. One example with the argument values filled in rules out the malformed calls a bare parameter list invites
- Names the gotchas. Defaults, units, ranges, and the error the tool returns on failure go in the description the agent reads
Peter Steinberger’s MCP best practices go deeper on building them.5
The next chapter builds the environment where the agent demonstrates those capabilities
Anthropic, “Effective context engineering for AI agents” (2025). https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents ↩︎ ↩︎ ↩︎ ↩︎
Anthropic, “Harness design for long-running application development” (2025). https://www.anthropic.com/engineering/harness-design-long-running-apps ↩︎
OpenAI, “Unrolling the Codex agent loop” (2026). https://openai.com/index/unrolling-the-codex-agent-loop/ ↩︎
Anthropic, “Writing effective tools for agents” (2025). https://www.anthropic.com/engineering/writing-tools-for-agents ↩︎
Peter Steinberger, “MCP Best Practices” (2025). https://steipete.me/posts/2025/mcp-best-practices ↩︎