Structure of an evaluation
An evaluation (eval) is a test for an AI system.1 There are usually two ways of evaluating LLMs:
- Single-turn: send a prompt and evaluate the response, where you already know the correct answer
- Agentic: give it an input, let it cook, and score what it has done
In this guide, given their abysmal relevance, we’ll focus on AI agents
An agent receives tools and operates within an environment, acts over many turns, and changes state as it goes, so mistakes propagate and compound. Grading an agent usually means grading what it has produced: the transcript/traces of its actions, or the product created within the environment
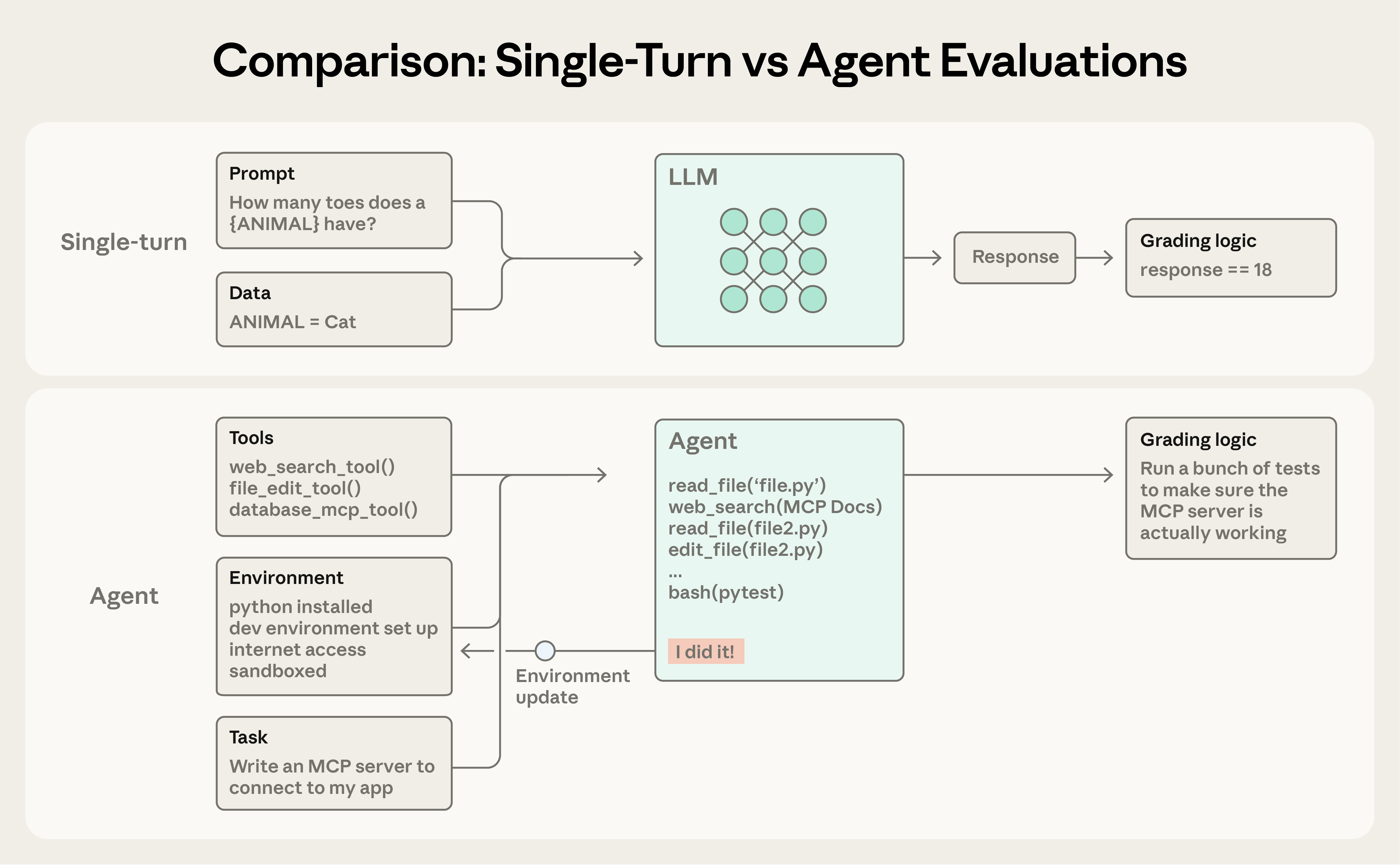 Source: Anthropic, “Demystifying evals for AI agents” (2025).
Source: Anthropic, “Demystifying evals for AI agents” (2025).
What an evaluation is made of
Evaluation harness. The machinery that runs the eval end to end: it boots the environment from its recipe, runs the trials, records the transcripts, and applies the graders. It stays separate from the agent harness
Environment. The workspace where the agent operates
Grader. The logic that scores a trial; a task can have several. Prefer outcome checks where possible
Transcript and outcome. The transcript is what the agent did: messages, tool calls, intermediate results. The outcome is the final state of the environment after the trial; measure the outcome, not only what the agent said.2
Agent access. The tools, documents, and actions available to the agent during the trial
Trial. One attempt at a task. Run several trials per task because agent output varies between attempts.3
Diversity over quantity
An evaluation can simply be one task, or a collection of tasks. Collections can be unstructured or structured. Unstructured ones, like what METR or Cybench do, sweep a whole range of activities looking for capabilities, and they are very good for research purposes.4
A pattern I’ve seen in the benchmarks used by all the major research labs is a group of tasks they call a suite or a task-family, aimed at evaluating one particular capability. This is because for your measurement to be accurate, it needs to evaluate the model in different ways, to account for diversity and originality; otherwise you end up evaluating the model on exactly the same thing with different colours, and then making huge claims on it
It is far more important to have different and unique tasks, even if the quantity is small (RE-Bench has only seven tasks5), as long as the tasks are challenging and the model is evaluated on what it generated
In HCAST, for example, the benchmark has 189 tasks grouped into 78 families, and each task has its own duration and scoring function: durations are calibrated against humans from one minute to over eight hours, most tasks score binary, some score continuously against a threshold.6
Research benchmarks and real work
When you study how METR and AISI make tasks, you find these evaluations are purely research: they test whether the model will actually do something under controlled experiments, often to theoretically evaluate the model on dangerous capabilities.7
A problem I see in benchmarks from industries that are not AI-native (health, legal, telecom) is that they struggle with the concept of a good evaluation, and it is natural: coding already gives you an ecosystem of applications to build environments from. Until recently every telecom benchmark was multiple-choice,8 a format coding benchmarks moved past a year earlier. The agentic attempts that followed usually share one shape: one environment built on synthetically generated data, one agent with a few tools, and one scoring function that most of the time checks a single thing, accuracy or the number of tool calls. It still bugs me that none of it can be used in a real setting, as opposed to SWE-bench, tau-bench, or GDPval, whose tasks come from real GitHub issues, realistic customer flows, and real work products.91011
The challenge is that when we talk about real-world capabilities, the lens has to change, and here is the plot twist: the research evaluations are often unrealistic, and they don’t let you measure whether the capabilities of models are scaling when you actually want to train a model, essentially because these organisations are evaluating models in research spaces to test for dangerous capabilities. And with real-world capabilities, often we don’t even know what those capabilities look like in the first place; that is what I learned at GSMA
The approach this guide follows. Centre everything on one use case, name the capabilities a hypothetical agent would need to solve it, and break the problem into a task-suite of tasks scored in isolation. Each task maps to named capabilities: when an agent fails you know which capability is missing, and when you train you know what data to collect
To see every part land in concrete tasks, read the worked examples. The first chapter starts the design order with the use case
Anthropic, “Demystifying evals for AI agents” (2025). https://www.anthropic.com/engineering/demystifying-evals-for-ai-agents ↩︎
Lightman et al., “Let’s Verify Step by Step” (2023). https://arxiv.org/abs/2305.20050 ↩︎
Atil et al., “Non-Determinism of ‘Deterministic’ LLM Settings” (2024). https://arxiv.org/abs/2408.04667 ↩︎
Zhang et al., “Cybench: A Framework for Evaluating Cybersecurity Capabilities and Risks of Language Models” (2024). https://arxiv.org/abs/2408.08926 ↩︎
Wijk et al. (METR), “RE-Bench: Evaluating frontier AI R&D capabilities of language model agents against human experts” (2024). https://arxiv.org/abs/2411.15114 ↩︎
Rein et al. (METR), “HCAST: Human-Calibrated Autonomy Software Tasks” (2025). https://arxiv.org/abs/2503.17354 ↩︎
METR, “About METR”. https://metr.org/about; AI Security Institute. https://www.aisi.gov.uk/ ↩︎
Maatouk et al., “TeleQnA: A Benchmark Dataset to Assess Large Language Models Telecommunications Knowledge” (2023). https://arxiv.org/abs/2310.15051 ↩︎
Jimenez et al., “SWE-bench: Can Language Models Resolve Real-World GitHub Issues?” (2023). https://arxiv.org/abs/2310.06770 ↩︎
Yao et al., “tau-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains” (2024). https://arxiv.org/abs/2406.12045 ↩︎
OpenAI, “GDPval: Evaluating AI Model Performance on Real-World Economically Valuable Tasks” (2025). https://arxiv.org/abs/2510.04374 ↩︎